Формат файла Write Anywhere - Write Anywhere File Layout
Эта статья нужны дополнительные цитаты для проверка. (Март 2012 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
| Разработчики) | NetApp |
|---|---|
| Полное имя | Формат файла Write Anywhere |
| Пределы | |
| Максимум. размер тома | до 100 ТБ (ограничено совокупным размером; переменный максимум зависит от платформы; ограничен 16 ТБ при использовании дедупликации {ONTAP 8.2 теперь поддерживает дедупликацию до максимального размера тома, поддерживаемого на платформе}) |
| Максимум. размер файла | до 16 ТБ[1] |
| Функции | |
| Даты записаны | atime, ctime, mtime |
| Разрешения файловой системы | Разрешения UNIX и ACL |
| Прозрачное сжатие | Да (Ontap 8.0 и выше) |
| Прозрачное шифрование | Да (начиная с Ontap 9.1[2]; возможно со сторонними устройствами, такими как Decru DataFort для более старых версий) |
| Дедупликация данных | Да (ФАС Dedup: периодические онлайн-проверки, по блокам;) |
| Копирование при записи | да |
| Другой | |
| Поддерживается операционные системы | ONTAP |
В Формат файла Write Anywhere (WAFL) является проприетарной файловая система который поддерживает большие, высокопроизводительные RAID массивы, быстрый перезапуск без длительных проверок согласованности в случае крушение или сбой питания и быстрое увеличение размера файловой системы. Он был разработан NetApp для использования в его устройствах хранения, таких как NetApp FAS, AFF, Cloud Volumes ONTAP и ONTAP Выбрать.
Его автор утверждает, что WAFL не является файловой системой, хотя и включает ее.[3] Он отслеживает изменения аналогично журнальные файловые системы в виде журналов (известных как NVLOG) на выделенном запоминающем устройстве энергонезависимая память с произвольным доступом, именуемый NVRAM или NVMEM. WAFL предоставляет механизмы, обеспечивающие доступ к различным файловым системам и технологиям. дисковые блоки.
Дизайн
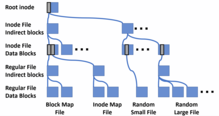
WAFL хранит метаданные, а также данные в файлах; метаданные, такие как индексы и карты блоков, указывающие, какие блоки в томе выделены, не хранятся в фиксированных местах файловой системы. Файл верхнего уровня в томе - это файл inode, который содержит inodes для всех остальных файлов; индексный дескриптор самого файла inode, называемый корневым индексом, хранится в блоке с фиксированным расположением. Inode для достаточно маленького файла содержит содержимое файла; в противном случае он содержит список указателей на блоки данных файла или список указателей на косвенные блоки, содержащий списки указателей на блоки данных файла, и так далее, с таким количеством слоев косвенных блоков, которое необходимо, образуя дерево блоков. Все блоки данных и метаданных в файловой системе, кроме блока, содержащего корневой индексный дескриптор, хранятся в файлах файловой системы. Таким образом, корневой индексный дескриптор можно использовать для поиска всех блоков всех файлов, кроме файла индексного дескриптора.[4]
Основная память используется как кеш страницы для блоков из файлов. Когда в блок файла вносятся изменения, копия в кэше страницы обновляется и помечается как грязная, а разница регистрируется в энергонезависимой памяти в журнале, который называется NVLOG. Если грязный блок в кэше страниц должен быть записан в постоянное хранилище, он не перезаписывается в блок, из которого он был прочитан; вместо этого новый блок выделяется в постоянном хранилище, содержимое блока записывается в новое место, а индексный дескриптор или косвенный блок, указывающий на рассматриваемый блок, обновляется в основной памяти. Если блок, содержащий индексный дескриптор или косвенный блок, должен быть записан в постоянное хранилище, он также записывается в новое место, а не перезаписывается в его предыдущей позиции. Это то, что относится к «Write Anywhere» в «Write Anywhere File Layout».[4]
Поскольку все блоки, кроме блока, содержащего корневой индексный дескриптор, находятся через корневой индексный дескриптор, никакие изменения, записанные в постоянное хранилище, не видны в постоянном хранилище, пока корневой индексный дескриптор не будет обновлен. Корневой индекс обновляется процессом, называемым точка согласованности, в котором все грязные блоки, еще не записанные в постоянное хранилище, записываются в постоянное хранилище, и записывается новый корневой индексный дескриптор, указывающий на блоки в новой версии файла индексного дескриптора. В этот момент все изменения файловой системы будут видны в постоянном хранилище с использованием нового корневого индексного дескриптора. Записи NVLOG для изменений, которые теперь видны, удаляются, чтобы освободить место для записей журнала для последующих изменений. Точки согласованности выполняются периодически или если энергонезависимая память почти заполнена записями журнала.[4]
Если сервер выходит из строя до того, как все изменения в файловой системе становятся видимыми в точке согласованности, изменения, которые не были сделаны видимыми, все еще находятся в NVLOG; когда сервер перезагружается, он воспроизводит все записи в NVLOG, снова делая изменения, записанные в NVLOG, так что они не будут потеряны.
Функции
Как обсуждалось выше, WAFL не хранит данные или метаданные в заранее определенных местах на диске. Вместо этого он автоматически размещает данные, используя временная местность написать метаданные наряду с пользовательскими данными таким образом, чтобы свести к минимуму количество дисковых операций, необходимых для передачи данных в стабильное дисковое хранилище с использованием RAID с одинарной и двойной четностью.
Использование размещения данных на основе временной локальности ссылки может улучшить производительность чтения наборов данных, которые читаются аналогично тому, как они были написаны (например, запись базы данных и связанная с ней запись индекса), однако это также может вызвать фрагментация с точки зрения пространственной локальности референции. На прядении Жесткие диски это не оказывает отрицательного воздействия на файлы, которые последовательно записываются, читаются случайным образом или впоследствии считываются с использованием того же временного шаблона, но действительно влияет на последовательное чтение после произвольной записи шаблоны доступа к пространственным данным, поскольку магнитная головка может находиться только в одной позиции за раз, считывать данные с пластины, пока фрагментация не влияет на SSD диски.
Выпуски ONTAP начиная с версии 7.3.1, в него включен ряд методов оптимизации компоновки пространственных данных, таких как перераспределить команда для выполнения по расписанию и вручную дефрагментация, а Пишите после прочтения параметр тома, который обнаруживает и автоматически исправляет неоптимальные шаблоны доступа к данным, вызванные пространственной фрагментацией. Выпуски ONTAP 8.1.1 включает другие методы для автоматической оптимизации непрерывного свободного пространства в файловой системе, что также помогает поддерживать оптимальное расположение данных для большинства шаблонов доступа к данным. До 7G сканирование вафл перераспределить Команда должна быть вызвана с расширенного уровня привилегий и не может быть запланирована. Выпуски ONTAP начиная с версии 9.1, включает ряд методов для оптимизации использования SSD, таких как встроенное сжатие данных (в версии 9.1), начиная с ONTAP 9.2. FabricPool функциональность для автоматического многоуровневого хранения холодных данных для замедления хранилища S3 и обратно, если необходимо для SSD агрегаты, и Кросс-томная дедупликация в пределах одного агрегата максимум 800 ТиБ для каждого агрегата.[5]
Снимки


WAFL поддерживает снимки, которые являются копиями файловой системы только для чтения. Снимки создаются путем выполнения тех же операций, которые выполняются в точке согласованности, но вместо обновления корневого индексного дескриптора, соответствующего текущему состоянию файловой системы, сохраняется копия корневого индексного дескриптора. Поскольку все данные и метаданные в файловой системе можно найти из корневого индексного дескриптора, все данные и метаданные в файловой системе на момент создания моментального снимка можно найти из копии корневого индексного дескриптора моментального снимка. Никаких других данных копировать для создания снимка не требуется.[4]
При записи блоки выделяются с использованием карты блоков, которая отслеживает, какие блоки используются, а какие свободны. Запись в карте блоков содержит бит, указывающий, используется ли блок в текущей версии файловой системы, и несколько битов, по одному на моментальный снимок, указывающих, используется ли блок в моментальном снимке. Это гарантирует, что данные в снимке не будут перезаписаны, пока снимок не будет удален. При использовании карты блоков все новые записи и перезаписи записываются в новые пустые блоки, WAFL сообщает только об успешной перезаписи блока, но на самом деле перезаписи не происходит, этот подход называется методом перенаправления при записи (ROW).[4] ROW намного быстрее выполняет операции перезаписи по сравнению с Копирование при записи там, где старый блок данных, который будет перезаписан на месте и записан в моментальный снимок, необходимо сначала скопировать в пространство, выделенное для резервирования моментального снимка, чтобы сохранить исходные данные, это генерирует дополнительные операции копирования данных, когда система перезаписывает этот блок.
Моментальные снимки обеспечивают оперативное резервное копирование, к которому можно быстро получить доступ через специальные скрытые каталоги в файловой системе, что позволяет пользователям восстанавливать файлы, которые были случайно удалены или изменены.[4]
Операционная система NetApp Data ONTAP Release 7G поддерживает моментальный снимок чтения-записи, называемый FlexClone. Снимки являются основой для таких технологий, как SnapMirror, SnapVault и Online Volume Move в то время как такие функции, как FlexClone, SnapLock, SnapRestore - это технологии, подобные моментальным снимкам, которые используют возможности и свойства WAFL, такие как манипуляции с индексными дескрипторами. Начиная с ONTAP 9.4 максимальное количество снимков, поддерживаемых для каждого FlexVol, составляет 1024, тогда как для предыдущих версий максимальное количество снимков было 255.
Начиная с ONTAP 9.5, были добавлены функции совместного использования снимков для запуска сканирования с дедупликацией в активной файловой системе и снимках, а экономия от дедупликации выражается в количестве снимков. До версии 9.5 недедуплицированные данные, заблокированные в моментальном снимке, не могли использоваться процессом дедупликации и выполнялись только в активной файловой системе.
Модель файлов и каталогов
Важной особенностью WAFL является поддержка как Unix -стилем модель файла и каталога для NFS клиентов и Майкрософт Виндоус -стилем модель файла и каталога для SMB клиентов. WAFL также поддерживает обе модели безопасности, включая режим, в котором разные файлы на одном томе могут иметь разные атрибуты безопасности. Unix может использовать либо[6] списки контроля доступа (ACL) или простая битовая маска, тогда как более поздняя модель Windows основана на списках управления доступом. Эти две функции позволяют записать файл в сетевую файловую систему типа SMB и получить к нему доступ позже через NFS с рабочей станции Unix. Помимо обычных файлов, WAFL может содержать файловые контейнеры, называемые LUN-ы с необходимыми специальными атрибутами, такими как серийный номер LUN для блочных устройств, к которым можно получить доступ, используя SAN протоколы, работающие на ONTAP Программное обеспечение ОС.
FlexVol
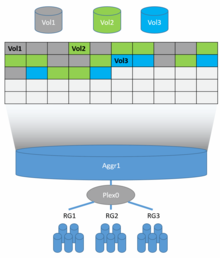
Каждый гибкий том (FlexVol) представляет собой отдельную файловую систему WAFL, расположенную на совокупность и распределяется по всем дискам в совокупности. Каждый агрегат может содержать и обычно имеет несколько томов FlexVol. ONTAP во время процесса оптимизации данных, включая «Тетрис», который заканчивается точками согласованности (см. NVRAM ) запрограммирован так, чтобы равномерно распределять как можно больше блоков данных в каждом томе FlexVol по всем дискам в совокупности, чтобы каждый FlexVol потенциально мог использовать всю доступную производительность всех дисков данных в совокупности. Благодаря подходу равномерного распределения блоков данных по всем дискам данных в совокупности, регулирование производительности для FlexVol может осуществляться динамически с помощью QoS хранилища и не требуется выделенных агрегатов или групп RAID для каждого FlexVol, чтобы гарантировать производительность и обеспечить неиспользованную производительность для том FlexVol, который этого требует. Каждый FlexVol можно настроить как толстый или с тонким резервом пространство, а позже можно было изменить на лету в любое время. Заблокируйте доступ к устройству с помощью сеть хранения данных ] (SAN), такие как iSCSI, Fibre Channel (FC) и Fibre Channel через Ethernet (FCoE) выполняется с эмуляцией LUN, аналогичной Устройство петли техника поверх тома FlexVol; таким образом, каждый LUN в файловой системе WAFL отображается как файл, но имеет дополнительные свойства, необходимые для блочных устройств. LUN также можно настроить как толстые или с тонким резервом и могут быть изменены позже на лету. Благодаря архитектуре WAFL, FlexVols и LUN могут увеличивать или уменьшать использование сконфигурированного пространства на лету. Если FlexVol содержит данные, внутреннее пространство может быть уменьшено не меньше, чем используемое пространство. Несмотря на то, что размер LUN с данными на нем можно уменьшить в файловой системе WAFL, ONTAP не имеет сведений о структуре блоков верхнего уровня из-за архитектуры SAN, поэтому он может усечь данные и повредить файловую систему на этом LUN, поэтому хосту необходимо перенести блоки, содержащие данные, в новую границу LUN, чтобы предотвратить потерю данных. У каждого FlexVol может быть свой QoS, FlashPool, FlasCache или же FabricPool политики.
Если создаются два тома FlexVol, каждый на двух агрегатах, и эти агрегаты принадлежат двум разным контроллерам, и системному администратору необходимо использовать пространство этих томов через протокол NAS. Затем они создавали два общих файлового ресурса, по одному на каждом томе. В этом случае администратор, скорее всего, даже создаст разные IP-адреса; каждый будет использоваться для доступа к выделенному файловому ресурсу. Каждый том будет иметь одну вафельность записи, и будет два ведра пространства. Хотя даже если два тома находятся на одном контроллере и, например, на одном агрегате (таким образом, если второй агрегат существует, он не будет использоваться в этом случае), и оба тома будут доступны через один IP-адрес, все равно будет будет два сродства записи, по одному на каждый том, и всегда будет два отдельных сегмента пространства. Следовательно, чем больше у вас томов, тем больше у вас будет бесполезной записи (лучшее распараллеливание и, следовательно, лучшее использование ЦП), но тогда у вас будет несколько томов (и несколько корзин для пространства, следовательно, несколько общих файловых ресурсов).
Сплетения
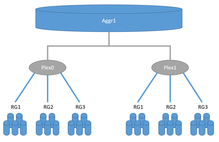
Похожий на RAID-1, сплетения в системах ONTAP могут хранить зеркальные данные в двух местах, но хотя обычный RAID-1 должен существовать в пределах одной системы хранения, два сплетения могут быть распределены между двумя системами хранения. Каждый совокупность состоит из одного или двух сплетений. Обычные системы хранения высокой доступности имеют только одно сплетение для каждого агрегата, в то время как локальные конфигурации SyncMirror или MetroCluster могут иметь два сплетения для каждого агрегата. С другой стороны, каждое сплетение включает базовое пространство для хранения от одного или нескольких NetApp. Группы RAID или LUN из сторонних систем хранения (см. FlexArray ) в одном сплетении аналогично RAID-0. Если агрегат состоит из двух сплетений, одно сплетение считается ведущим, а второе - ведомым; ведомые устройства должны состоять из точно такой же конфигурации RAID и дисков. Например, если у нас есть агрегат, состоящий из двух сплетений, где главное сплетение состоит из 21 данных и 3 диска четности SAS 1,8 ТБ в RAID-TEC, то ведомое сплетение должно состоять из 21 диска данных и 3 дисков четности SAS 1,8 ТБ в RAID. -TEC. Второй пример, если у нас есть агрегат, состоящий из двух сплетений, где главное сплетение состоит из одного массива данных RAID 17 и 3 дисков SAS с контролем четности 1,8 ТБ, настроенных как RAID-TEC, а второй RAID в главном сплетении - это RAID-DP с 2 данными и 2 четность SSD 960 ГБ. Второй сплетение должно иметь ту же конфигурацию: один RAID 17 для данных и 3 диска SAS с контролем четности 1,8 ТБ, настроенный как RAID-TEC, а второй RAID в ведомом сплетении - это RAID-DP с 2 данными и 2 твердотельными накопителями с контролем четности 960 ГБ.Метрокластер конфигурации используют технологию SyncMirror для синхронной репликации данных. Существует два варианта SyncMirror: MetroCluster и Local SyncMirror, оба используют одну и ту же технику сплетения для синхронной репликации данных между двумя сплетениями. Local SyncMirror создает оба сплетения в одном контроллере и часто используется для дополнительной безопасности, чтобы предотвратить сбой всей дисковой полки в системе хранения. MetroCluster позволяет реплицировать данные между двумя системами хранения. Каждая система хранения может состоять из одного контроллера или быть настроена как пара высокой доступности с двумя контроллерами. В одной паре высокой доступности можно разместить два контроллера на отдельном шасси, при этом расстояние друг от друга может составлять десятки метров, в то время как в конфигурации MetroCluster расстояние может достигать 300 км.
Энергонезависимая память
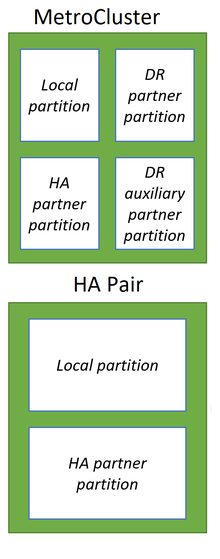
Как и многие конкуренты, системы NetApp ONTAP используют память как гораздо более быстрый носитель данных для приема и кэширования данных от хостов и, что наиболее важно, для оптимизации данных перед записью, что значительно повышает производительность таких систем хранения. Пока конкуренты широко используют энергонезависимая память с произвольным доступом (NVRAM), чтобы сохранить данные в нем во время неожиданных событий, таких как перезагрузка для кэширования записи и оптимизации данных, системы NetApp ONTAP, использующие обычные оперативная память (RAM) для оптимизации данных и выделенный NVRAM или NVDIMM для регистрации исходных данных в неизменном состоянии, поскольку они поступают с хостов, аналогично тому, как ведется журнал транзакций в Реляционные базы данных. Так что в случае аварии, естественно, оперативная память будет автоматически очищена после перезагрузки, а данные сохранятся в энергонезависимой памяти в виде журналов, называемых NVLOG сохранится после перезагрузки и будет использоваться для восстановления согласованности. Все изменения и оптимизации в системах ONTAP производятся только в оперативной памяти, что помогает уменьшить размер энергонезависимой памяти для систем ONTAP. После оптимизации данные с хостов структурированы в стиле тетриса, оптимизированы и подготовлены с прохождением нескольких этапов (например, WAFL и RAID) для записи на базовые диски в группах RAID на совокупность где будут храниться данные. После оптимизации данные будут последовательно записываться на диски в рамках транзакции точки согласования (CP). Данные, записанные в агрегаты, будут содержать необходимые метаданные WAFL и RAID четность, поэтому никаких дополнительных операций чтения с дисков данных, вычислений и записи на диски четности не будет, как в традиционных группах RAID-6 и RAID-4. Сначала CP создает моментальный снимок системы на агрегате, в который будут записаны данные, затем оптимизированные и подготовленные данные из ОЗУ записываются последовательно в виде одной транзакции в агрегат, в случае сбоя вся транзакция завершается неудачно в случае внезапной перезагрузки, что позволяет Файловая система WAFL всегда должна быть согласованной. В случае успешной транзакции CP новая активная точка файловой системы распространяется и соответствующие NVLOG очищаются. Все данные всегда будут записаны в новое место, и перезапись невозможна. Блоки данных удаляются узлами, помеченными как свободные, чтобы их можно было использовать позже в следующих циклах CP, и в системе не будет исчерпано пространство с политикой WAFL «всегда писать новые данные в новое место». Только NVLOG в системах хранения высокой доступности реплицируются синхронно между двумя контроллерами для возможности аварийного переключения системы хранения высокой доступности, что помогает снизить общие накладные расходы на защиту системной памяти. В системе хранения с двумя контроллерами в конфигурации высокой доступности или Метрокластер с одним контроллером на каждом сайте, каждый из двух контроллеров делит свою энергонезависимую память на две части: локальную и ее партнерскую. В конфигурации MetroCluster с четырьмя узлами каждая энергонезависимая память разделена на следующие части: локальные, локальные партнерские и удаленные партнерские.[7]
Начиная с системы All-Flash FAS A800, NetApp заменила модуль NVRAM PCI на модули NVDIMM, подключенные к шине памяти, что повысило производительность.
Смотрите также
- Сравнение файловых систем
- Список файловых систем
- NetApp
- NetApp FAS
- ONTAP Операционная система, используемая в системах хранения NetApp
Примечания
- ^ «Пределы хранилища». library.netapp.com.
- ^ "Шифрование томов NetApp, суровая суровость | IOPS.ca".
- ^ "Является ли WAFL файловой системой?". Blogs.netapp.com. Архивировано из оригинал 15 июля 2014 г.
- ^ а б c d е ж Дэйв Хитц; Джеймс Лау; Майкл Малькольм (19 января 1994 г.). Проектирование файловой системы для устройства файлового сервера NFS (PDF). USENIX Зима 1994.
- ^ Паризи, Джастин (14 июля 2017 г.). «Запуск VMware на ONTAP? Почему вам следует подумать об обновлении до ONTAP 9.2».
- ^ «Списки контроля доступа POSIX в Linux». Suse.de. Архивировано из оригинал 24 января 2007 г.
- ^ «Clustered Data ONTAP® 8.3. Руководство по управлению и аварийному восстановлению MetroCluster ™: зеркалирование кэша NVRAM и NVMEM в конфигурации MetroCluster». NetApp. 1 сентября 2015 г. Архивировано с оригинал (URL) на 2018-01-24. Получено 24 января 2018.
внешняя ссылка
- Официальный веб-сайт
- Проектирование файловой системы для устройства файлового сервера NFS (PDF)
- Патент США 5,819,292 - Метод поддержания согласованных состояний файловой системы и создания доступных пользователю копий файловой системы только для чтения - 6 октября 1998 г.