Исправление ошибок Рида – Соломона - Reed–Solomon error correction
| Коды Рида – Соломона | |
|---|---|
| Названный в честь | Ирвинг С. Рид и Гюстав Соломон |
| Классификация | |
| Иерархия | Линейный блочный код Полиномиальный код Код Рида – Соломона |
| Длина блока | п |
| Длина сообщения | k |
| Расстояние | п − k + 1 |
| Размер алфавита | q = пм ≥ п (п премьер) Часто п = q − 1. |
| Обозначение | [п, k, п − k + 1]q-код |
| Алгоритмы | |
| Берлекамп – Мэсси Евклидово и другие. | |
| Свойства | |
| Разделимый код максимального расстояния | |
Коды Рида – Соломона группа коды с исправлением ошибок которые были представлены Ирвинг С. Рид и Гюстав Соломон в 1960 г.[1]У них много приложений, наиболее известными из которых являются потребительские технологии, такие как Компакт-диски, DVD, Блю рей диски, QR коды, передача информации такие технологии как DSL и WiMAX, трансляция такие системы, как спутниковая связь, DVB и ATSC, и системы хранения, такие как RAID 6.
Коды Рида – Соломона работают с блоком данных, рассматриваемым как набор конечное поле элементы, называемые символами. Коды Рида – Соломона способны обнаруживать и исправлять множественные символьные ошибки. Добавлением т = п − k проверять символы в данных, код Рида – Соломона может обнаруживать (но не исправлять) любую комбинацию до включительно т ошибочные символы, или найти и исправить до включительно ⌊т/2⌋ ошибочные символы в неизвестных местах. Как код стирания, он может исправить до т стирание в местах, которые известны и предоставлены алгоритму, или он может обнаруживать и исправлять комбинации ошибок и стираний. Коды Рида – Соломона также подходят в качестве многократныхвзрыв коды с исправлением битовых ошибок, поскольку последовательность б + 1 последовательные битовые ошибки могут повлиять не более чем на два символа размера б. Выбор т зависит от разработчика кода и может быть выбран в широких пределах.
Существует два основных типа кодов Рида – Соломона - исходный вид и BCH view - наиболее распространенным является представление BCH, поскольку декодеры представления BCH работают быстрее и требуют меньше памяти, чем исходные декодеры представления.
История
Коды Рида – Соломона были разработаны в 1960 г. Ирвинг С. Рид и Гюстав Соломон, которые тогда были сотрудниками Лаборатория Линкольна Массачусетского технологического института. Их основополагающая статья называлась «Полиномиальные коды над некоторыми конечными полями». (Рид и Соломон 1960 ). Исходная схема кодирования, описанная в статье Рида и Соломона, использовала переменный многочлен на основе сообщения, которое нужно кодировать, где кодировщику и декодеру известен только фиксированный набор значений (точек оценки), которые должны быть закодированы. Первоначальный теоретический декодер генерировал потенциальные многочлены на основе подмножеств k (длина незашифрованного сообщения) из п (длина закодированного сообщения) значения полученного сообщения, выбирая наиболее популярный полином в качестве правильного, что было непрактично во всех случаях, кроме простейшего. Первоначально это было решено путем изменения исходной схемы на Код BCH подобная схема основана на фиксированном полиноме, известном как кодеру, так и декодеру, но позже были разработаны практические декодеры на основе исходной схемы, хотя и более медленные, чем схемы BCH. Результатом этого является то, что существует два основных типа кодов Рида-Соломона: те, которые используют исходную схему кодирования, и те, которые используют схему кодирования BCH.
Также в 1960 году практический фиксированный полиномиальный декодер для Коды BCH разработан Даниэль Горенштейн и Нил Зирлер был описан в отчете лаборатории Линкольна Массачусетского технологического института Зирлера в январе 1960 года, а затем в статье в июне 1961 года.[2] Декодер Горенштейна – Цирлера и связанная с ним работа над кодами BCH описаны в книге «Коды с исправлением ошибок» автора. В. Уэсли Петерсон (1961).[3] К 1963 году (или, возможно, раньше) Дж. Дж. Стоун (и другие) признали, что коды Рида-Соломона могут использовать схему БЧХ с использованием фиксированного порождающего полинома, что делает такие коды особым классом кодов БЧХ,[4] но коды Рида-Соломона, основанные на исходной схеме кодирования, не являются классом кодов BCH, и в зависимости от набора точек оценки они даже не циклические коды.
В 1969 году усовершенствованный декодер схемы BCH был разработан Элвин Берлекамп и Джеймс Мэсси, и с тех пор известен как Алгоритм декодирования Берлекампа-Месси.
В 1975 году Ясуо Сугияма разработал еще один улучшенный декодер схемы BCH, основанный на расширенный алгоритм Евклида.[5]
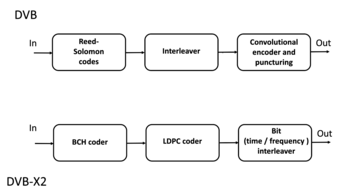
В 1977 году коды Рида – Соломона были реализованы в Программа "Вояджер" в виде составные коды исправления ошибок. Первое коммерческое применение в массовых потребительских товарах появилось в 1982 году с компакт-диск, где два чередующийся Используются коды Рида – Соломона. Сегодня коды Рида – Соломона широко применяются в цифровое хранилище устройства и цифровая связь стандартов, хотя они постепенно заменяются более современными коды с низкой плотностью проверки четности (LDPC) или турбокоды. Например, коды Рида – Соломона используются в Цифровое видеовещание (DVB) стандарт DVB-S, но коды LDPC используются в его преемнике, DVB-S2.
В 1986 году оригинальная схема декодера, известная как Алгоритм Берлекампа – Велча был развит.
В 1996 году Мадху Судан и другие разработали варианты декодеров исходных схем, называемые декодерами списков или программными декодерами, и работа над этими типами декодеров продолжается - см. Алгоритм декодирования списка Гурусвами – Судан.
В 2002 году Шухонг Гао разработал еще одну оригинальную схему декодера, основанную на расширенный алгоритм Евклида Gao_RS.pdf .
Приложения
Хранилище данных
Кодирование Рида – Соломона очень широко используется в системах хранения данных для исправления пакетных ошибок, связанных с дефектами носителя.
Кодирование Рида – Соломона - ключевой компонент компакт-диск. Это было первое использование сильного кодирования с исправлением ошибок в массовом потребительском продукте, и DAT и DVD использовать аналогичные схемы. На компакт-диске два уровня кодирования Рида – Соломона, разделенные 28-полосным сверточный перемежитель дает схему, называемую кодированием Рида – Соломона с перекрестным чередованием (CIRC ). Первым элементом декодера CIRC является относительно слабый внутренний (32,28) код Рида – Соломона, сокращенный от кода (255,251) с 8-битовыми символами. Этот код может исправить до 2-х байтовых ошибок на 32-байтовый блок. Что еще более важно, он помечает как стирающие любые неисправимые блоки, то есть блоки с ошибками более 2 байтов. Декодированные 28-байтовые блоки с индикацией стирания затем распространяются обращенным перемежителем на разные блоки внешнего кода (28,24). Благодаря обратному чередованию стертый 28-байтовый блок внутреннего кода становится одним стертым байтом в каждом из 28 внешних кодовых блоков. Внешний код легко исправляет это, так как он может обрабатывать до 4 таких стираний на блок.
Результатом является CIRC, который может полностью исправить пакеты ошибок размером до 4000 бит или около 2,5 мм на поверхности диска. Этот код настолько силен, что большинство ошибок при воспроизведении компакт-дисков почти наверняка вызваны ошибками отслеживания, которые приводят к смене трека лазером, а не пакетами неисправимых ошибок.[6]
DVD используют аналогичную схему, но с гораздо большими блоками, внутренним кодом (208,192) и внешним кодом (182,172).
Исправление ошибок Рида – Соломона также используется в архивировать файлы, которые обычно размещаются вместе с мультимедийными файлами на USENET. Служба распределенного онлайн-хранилища Wuala (выпуск прекращен в 2015 г.) также использовался для использования кода Рида – Соломона при разделении файлов.
Штрих-код
Почти все двумерные штрих-коды, такие как PDF-417, MaxiCode, Datamatrix, QR код, и Кодекс ацтеков используйте исправление ошибок Рида – Соломона, чтобы обеспечить правильное считывание, даже если часть штрих-кода повреждена. Когда сканер штрих-кода не может распознать символ штрих-кода, он будет рассматривать его как стирание.
Кодирование Рида – Соломона менее распространено в одномерных штрих-кодах, но используется PostBar символика.
Передача информации
Специализированные формы кодов Рида – Соломона, в частности Коши -RS и Vandermonde -RS, может использоваться для преодоления ненадежного характера передачи данных по каналы стирания. Процесс кодирования предполагает код RS (N, K), что приводит к N кодовые слова длины N символы, каждый хранящий K символы генерируемых данных, которые затем отправляются по каналу стирания.
Любая комбинация K кодовых слов, полученных на другом конце, достаточно, чтобы восстановить все N кодовые слова. Кодовая скорость обычно устанавливается равной 1/2, если вероятность стирания канала не может быть адекватно смоделирована и не считается меньшей. В заключении, N обычно 2K, что означает, что по крайней мере половина всех отправленных кодовых слов должна быть получена, чтобы восстановить все отправленные кодовые слова.
Коды Рида – Соломона также используются в xDSL системы и CCSDS с Спецификации протокола космической связи как форма упреждающее исправление ошибок.
Космическая передача
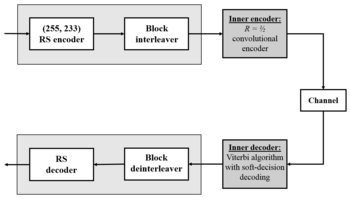
Одним из важных применений кодирования Рида-Соломона было кодирование цифровых изображений, отправленных обратно Вояджер Космический зонд.
Вояджер представил кодирование Рида-Соломона соединенный с участием сверточные коды, практика, которая с тех пор стала очень распространенной в дальнем космосе и спутниковой связи (например, прямое цифровое вещание).
Декодеры Витерби имеют тенденцию производить ошибки короткими пакетами. Исправление этих пакетных ошибок лучше всего выполнять с помощью коротких или упрощенных кодов Рида – Соломона.
Современные версии конкатенированного сверточного кодирования с декодированием Рида – Соломона / Витерби использовались и используются на Марс-следопыт, Галилео, Марсоход для исследования Марса и Кассини миссии, где они выполняются в пределах 1–1,5 дБ конечного предела, будучи Емкость Шеннона.
Эти объединенные коды теперь заменяются более мощными турбокоды:
| Лет | Код | Миссия (и) |
|---|---|---|
| 1958-настоящее время | Некодированный | Explorer, Mariner, многие другие |
| 1968-1978 | сверточные коды (CC) (25, 1/2) | Пионер, Венера |
| 1969-1975 (32, 6) | Код Рида-Мюллера | Моряк, Викинг |
| 1977-настоящее время | Двоичный код Голея | Вояджер |
| 1977-настоящее время | RS (255, 223) + CC (7, 1/2) | "Вояджер", "Галилей" и многие другие. |
| 1989-2003 | RS (255, 223) + CC (7, 1/3) | Вояджер |
| 1958-настоящее время | RS (255, 223) + CC (14, 1/4) | Галилео |
| 1996-настоящее время | RS + CC (15, 1/6) | Кассини, Марс-следопыт, другие |
| 2004-настоящее время | Турбо коды[nb 1] | Посланник, стерео, ТОиР, другие |
| оценка 2009 г. | Коды LDPC | Созвездие, MSL |
Конструкции
Код Рида – Соломона на самом деле представляет собой семейство кодов, в котором каждый код характеризуется тремя параметрами: алфавит размер q, а длина блока п, а длина сообщения k, с участием к <п ≤ q. Набор символов алфавита интерпретируется как конечное поле порядка q, и поэтому, q должен быть основная сила. В наиболее полезных параметризациях кода Рида – Соломона длина блока обычно является некоторым постоянным кратным длине сообщения, то есть показатель р = k/п - некоторая константа, и, кроме того, длина блока равна или на единицу меньше размера алфавита, то есть п = q или п = q − 1.[нужна цитата ]
Исходный взгляд Рида и Соломона: кодовое слово как последовательность значений
Для кода Рида – Соломона существуют разные процедуры кодирования, и, следовательно, есть разные способы описания набора всех кодовых слов. Рид и Соломон (1960), каждое кодовое слово кода Рида – Соломона представляет собой последовательность значений функции полинома степени меньше k. Чтобы получить кодовое слово кода Рида – Соломона, сообщение интерпретируется как описание полинома п степени меньше чем k над конечным полем F с участием q элементов, а многочлен п оценивается в п ≤ q отдельные точки поля F, а последовательность значений - соответствующее кодовое слово. Обычный выбор для набора оценок: {0, 1, 2, ..., п − 1}, {0, 1, α, α2, ..., αп−2}, или для п < q, {1, α, α2, ..., αп−1}, ... , где α это примитивный элемент из F.

Формально набор кодовых слов кода Рида – Соломона определяется следующим образом:


Поскольку любые два отчетливый многочлены степени меньше чем согласен в лучшем случае точек, это означает, что любые два кодовых слова кода Рида – Соломона не совпадают по крайней мере в Кроме того, есть два многочлена, которые согласуются в точки, но не равны, и, следовательно, расстояние кода Рида – Соломона точно .Тогда относительное расстояние , где Этот компромисс между относительным расстоянием и скоростью является асимптотически оптимальным, поскольку Граница синглтона, каждый код удовлетворяет Поскольку код Рида-Соломона достигает этого оптимального компромисса, он принадлежит к классу коды максимального расстояния.







В то время как количество различных многочленов степени меньше k и количество разных сообщений равно , и, таким образом, каждое сообщение может быть однозначно сопоставлено с таким многочленом, есть разные способы сделать это кодирование. Рид и Соломон (1960) интерпретирует сообщение Икс как коэффициенты полинома п, тогда как последующие конструкции интерпретируют сообщение как ценности полинома на первом k точки и получим многочлен п путем интерполяции этих значений полиномом степени меньше, чем kПоследняя процедура кодирования, будучи немного менее эффективной, имеет то преимущество, что систематический код, то есть исходное сообщение всегда содержится как подпоследовательность кодового слова.


Простая процедура кодирования: сообщение как последовательность коэффициентов
В оригинальной конструкции Рид и Соломон (1960), сообщение отображается в полином с участием



Кодовое слово получается путем оценки в разные точки поля .Таким образом, классическая функция кодирования для кода Рида – Соломона определяется следующим образом:





Эта функция это линейное отображение, то есть удовлетворяет для следующих -матрица с элементами из :





Эта матрица является транспонированной Матрица Вандермонда над . Другими словами, код Рида – Соломона является линейный код, а в классической процедуре кодирования его матрица генератора является .
Систематическая процедура кодирования: сообщение как начальная последовательность значений.
Существует альтернативная процедура кодирования, которая также производит код Рида – Соломона, но делает это в систематический путь. Здесь отображение из сообщения к многочлену работает иначе: полином теперь определяется как единственный многочлен степени меньше, чем такой, что
- относится ко всем .


Чтобы вычислить этот полином от , можно использовать Интерполяция Лагранжа.Как только он был найден, он оценивается в других точках. поля. Альтернативная функция кодирования для кода Рида – Соломона опять же просто последовательность значений:

С первого записи каждого кодового слова совпадают с , эта процедура кодирования действительно систематический.Поскольку интерполяция Лагранжа является линейным преобразованием, является линейным отображением. Фактически у нас есть , где



Дискретное преобразование Фурье и его обратное
А дискретное преобразование Фурье по сути такая же, как и процедура кодирования; он использует полином генератора п(x), чтобы сопоставить набор точек оценки со значениями сообщения, как показано выше:
Обратное преобразование Фурье можно использовать для преобразования безошибочного набора п < q значения сообщения обратно в полином кодирования k коэффициентов, с ограничением, что для того, чтобы это работало, набор точек оценки, используемых для кодирования сообщения, должен быть набором возрастающих степеней α:


Однако интерполяция Лагранжа выполняет то же преобразование без ограничения на набор точек оценки или требования безошибочного набора значений сообщения и используется для систематического кодирования, и на одном из этапов Декодер гао.
Представление BCH: кодовое слово как последовательность коэффициентов
В этом представлении отправитель снова отображает сообщение к многочлену , и для этого можно использовать любое из двух описанных отображений (где сообщение интерпретируется как коэффициенты или как исходная последовательность значений ). После того, как отправитель построил многочлен каким-то образом, однако, вместо того, чтобы отправлять ценности из во всех точках отправитель вычисляет некоторый связанный многочлен степени не более для и отправляет коэффициенты этого полинома. Полином строится путем умножения полинома сообщения , имеющий степень не выше , с порождающий полином степени это известно как отправителю, так и получателю. Образующий полином определяется как многочлен, корни которого в точности , т.е.










Передатчик отправляет коэффициенты . Таким образом, с точки зрения BCH кодов Рида – Соломона множество кодовых слов определено для следующим образом:[9]


Систематическая процедура кодирования
Процедура кодирования для представления кодов Рида – Соломона BCH может быть изменена для получения систематическая процедура кодирования, в котором каждое кодовое слово содержит сообщение в качестве префикса и просто добавляет символы исправления ошибок в качестве суффикса. Здесь вместо отправки , кодировщик строит переданный полином такие, что коэффициенты при наибольшие одночлены равны соответствующим коэффициентам при , а младшие коэффициенты выбраны именно так, что делится на . Тогда коэффициенты при являются подпоследовательностью (а именно префиксом) коэффициентов . Чтобы получить в целом систематический код, мы строим полином сообщения интерпретируя сообщение как последовательность его коэффициентов.



Формально построение осуществляется путем умножения от чтобы освободить место для отметьте символы, разделив этот продукт на чтобы найти остаток, а затем компенсировать этот остаток путем его вычитания. В контрольные символы создаются путем вычисления остатка :





Остальные имеют степень не выше , а коэффициенты при в полиноме равны нулю. Следовательно, следующее определение кодового слова обладает тем свойством, что первые коэффициенты идентичны коэффициентам :




В результате кодовые слова действительно являются элементами , то есть они делятся на порождающий полином :[10]

Свойства
Код Рида – Соломона - это [п, k, п − k + 1] код; другими словами, это линейный блочный код длины п (над F) с участием измерение k и минимум Расстояние Хэмминга Код Рида – Соломона оптимален в том смысле, что минимальное расстояние имеет максимальное значение, возможное для линейного кода размера (п, k); это известно как Граница синглтона. Такой код еще называют код максимального разделяемого расстояния (MDS).

Исправляющая способность кода Рида – Соломона определяется его минимальным расстоянием или, что эквивалентно, , мера избыточности в блоке. Если расположение символов ошибки заранее не известно, то код Рида – Соломона может исправить до ошибочные символы, то есть он может исправить вдвое меньше ошибок, чем добавлено избыточных символов в блок. Иногда места ошибок известны заранее (например, "дополнительная информация" в демодулятор отношения сигнал / шум ) - они называются стирания. Код Рида – Соломона (как и любой Код MDS ) может исправить вдвое больше стираний, чем ошибок, и любую комбинацию ошибок и стираний можно исправить до тех пор, пока соотношение 2E + S ≤ п − k удовлетворено, где количество ошибок и - количество стираний в блоке.




Теоретическая граница ошибки может быть описана следующей формулой для AWGN канал для ФСК:[11]

и для других схем модуляции:

где , , , - частота ошибок символа в случае некодированного AWGN и - порядок модуляции.




Для практического использования кодов Рида – Соломона обычно используется конечное поле с участием элементы. В этом случае каждый символ может быть представлен как -битовое значение. Отправитель отправляет точки данных как закодированные блоки, и количество символов в закодированном блоке равно . Таким образом, код Рида – Соломона, работающий с 8-битными символами, имеет символов на блок. (Это очень популярное значение из-за преобладания байтовый компьютерные системы.) Количество , с участием , из данные символы в блоке - это параметр дизайна. Часто используемый код кодирует восьмибитовых символов данных плюс 32 восьмибитовых символа четности в -символьный блок; это обозначается как код и способен исправлять до 16 ошибок символов в блоке.








Свойства кода Рида – Соломона, обсужденные выше, делают его особенно подходящим для приложений, в которых возникают ошибки в всплески. Это связано с тем, что для кода не имеет значения, сколько битов в символе ошибочно - если несколько битов в символе повреждены, это считается только одной ошибкой. И наоборот, если поток данных характеризуется не пакетами ошибок или выпадениями, а случайными одиночными ошибками, код Рида – Соломона обычно является плохим выбором по сравнению с двоичным кодом.
Код Рида – Соломона, как и сверточный код, это прозрачный код. Это означает, что если символы канала были перевернутый где-то по ходу дела декодеры все равно будут работать. Результатом будет инверсия исходных данных. Однако код Рида – Соломона теряет прозрачность при сокращении кода. «Недостающие» биты в сокращенном коде необходимо заполнить нулями или единицами, в зависимости от того, дополняются ли данные или нет. (Другими словами, если символы инвертированы, то заполнение нулями должно быть инвертировано в заполнение одним.) По этой причине обязательно, чтобы смысл данных (то есть истинный или дополняемый) был разрешен до декодирования Рида – Соломона.
Является ли код Рида – Соломона циклический или нет, зависит от тонких деталей конструкции. В исходной точке зрения Рида и Соломона, где кодовые слова являются значениями полинома, можно выбрать последовательность точек оценки таким образом, чтобы сделать код циклическим. В частности, если это первобытный корень поля , то по определению все ненулевые элементы принять форму для , где . Каждый полином над дает начало кодовое слово . Поскольку функция также является многочленом той же степени, эта функция дает кодовое слово ; поскольку это кодовое слово циклический сдвиг влево исходного кодового слова, полученного из . Таким образом, выбор последовательности примитивных корневых степеней в качестве точек оценки делает исходный вид кода Рида – Соломона циклический. Коды Рида – Соломона в представлении BCH всегда циклические, потому что Коды BCH циклические.









Замечания
От разработчиков не требуется использовать «естественные» размеры блоков кода Рида – Соломона. Метод, известный как «сокращение», может производить меньший код любого желаемого размера из большего кода. Например, широко используемый код (255,223) можно преобразовать в код (160,128), добавив в неиспользуемую часть исходного блока 95 двоичных нулей и не передав их. В декодере эта же часть блока загружается локально двоичными нулями. Дельсарт-Гёталь-Зайдель[12] Теорема иллюстрирует пример применения сокращенных кодов Рида – Соломона. Параллельно с сокращением используется метод, известный как прокалывание позволяет опустить некоторые закодированные символы четности.
Декодеры просмотра BCH
Декодеры, описанные в этом разделе, используют представление BCH кодового слова как последовательности коэффициентов. В них используется фиксированный полином генератора, известный как кодировщику, так и декодеру.
Декодер Петерсона – Горенштейна – Цирлера
Дэниел Горенштейн и Нил Цирлер разработали декодер, который был описан Цирлером в отчете лаборатории Линкольна Массачусетского технологического института в январе 1960 года, а затем в статье в июне 1961 года.[13] Декодер Горенштейна – Цирлера и связанные с ним работы по кодам BCH описаны в книге. Коды исправления ошибок от В. Уэсли Петерсон (1961).[14]
Формулировка
Переданное сообщение, , рассматривается как коэффициенты полинома s(Икс):


В результате процедуры кодирования Рида-Соломона, s(Икс) делится на порождающий полином г(Икс):

где α первобытный корень.
поскольку s(Икс) кратна образующей г(Икс), то он "наследует" все свои корни:

Переданный полином искажается при передаче полиномом ошибки е(Икс) для получения полученного многочлена р(Икс).


где ея - коэффициент при я-я степень Икс. Коэффициент ея будет равен нулю, если нет ошибки при этой степени Икс и ненулевое значение, если есть ошибка. Если есть ν ошибки при разных мощностях яk из Икс, тогда

Задача декодера - найти количество ошибок (ν), положения ошибок (яk), а значения ошибок в этих положениях (еяk). От тех, е(Икс) можно вычислить и вычесть из р(Икс), чтобы получить изначально отправленное сообщение s(Икс).
Расшифровка синдрома
Декодер начинает с оценки полинома, полученного в определенных точках. Мы называем результаты этой оценки «синдромами», Sj. Они определяются как:

Преимущество рассмотрения синдромов состоит в том, что полином сообщения выпадает. Другими словами, синдромы связаны только с ошибкой и не зависят от фактического содержания передаваемого сообщения. Если все синдромы равны нулю, алгоритм останавливается на этом и сообщает, что сообщение не было повреждено при передаче.
Локаторы ошибок и значения ошибок
Для удобства определим локаторы ошибок Иксk и значения ошибок Yk так как:

Тогда синдромы могут быть записаны в терминах этих локаторов ошибок и значений ошибок как

Это определение значений синдрома эквивалентно предыдущему, поскольку .

Синдромы дают систему п − k ≥ 2ν уравнения в 2ν неизвестных, но эта система уравнений нелинейна в Иксk и не имеет очевидного решения. Однако если Иксk были известны (см. ниже), то синдромные уравнения представляют собой линейную систему уравнений, которую легко решить для Yk значения ошибок.

Следовательно, проблема заключается в поиске Иксk, потому что тогда была бы известна самая левая матрица, и обе части уравнения можно было бы умножить на ее обратную, давая Yk
В варианте этого алгоритма, где места ошибок уже известны (когда он используется как код стирания ), это конец. Расположение ошибок (Иксk) уже известны каким-либо другим методом (например, в FM-передаче участки, где битовый поток был нечетким или преодолен помехами, можно определить с помощью частотного анализа с вероятностью). В этом сценарии до ошибки можно исправить.
Остальная часть алгоритма служит для поиска ошибок и потребует значений синдрома до , а не просто используется до сих пор. Вот почему необходимо добавить в 2 раза больше символов исправления ошибок, чем можно исправить, не зная их местоположения.


Полином локатора ошибок
Существует линейное рекуррентное соотношение, порождающее систему линейных уравнений. Решение этих уравнений позволяет определить места ошибок. Иксk.
Определить многочлен локатора ошибок Λ (Икс) так как

Нули Λ (Икс) являются обратными . Это следует из приведенной выше конструкции обозначения произведения, поскольку если тогда один из умноженных членов будет равен нулю , что приводит к нулевому значению всего полинома.




Позволять быть любым целым таким, что . Умножьте обе стороны на и все равно будет ноль.




Сумма за k = От 1 до ν и все равно будет ноль.

Соберите каждый член в отдельную сумму.

Извлеките постоянные значения на которые суммирование не влияет.


Эти суммы теперь эквивалентны значениям синдромов, которые мы знаем и можем подставить! Следовательно, это сводится к

Вычитание с обеих сторон дает


Напомним, что j было выбрано любое целое число от 1 до v включительно, и эта эквивалентность верна для любых без исключения таких значений. Следовательно, мы имеем v линейные уравнения, а не одно. Таким образом, эта система линейных уравнений может быть решена относительно коэффициентов Λя полинома определения места ошибки:

Вышесказанное предполагает, что декодер знает количество ошибок. ν, но это количество еще не определено. Декодер PGZ не определяет ν напрямую, а скорее ищет его, пробуя последовательные значения. Декодер сначала принимает наибольшее значение для пробной версии. ν и устанавливает линейную систему для этого значения. Если уравнения могут быть решены (т. Е. Определитель матрицы отличен от нуля), то пробным значением является количество ошибок. Если линейная система не может быть решена, то испытание ν сокращается на единицу и исследуется следующая меньшая система. (Гилл н.д., п. 35)
Найдите корни полинома локатора ошибок
Используйте коэффициенты Λя найденный на последнем шаге для построения полинома местоположения ошибки. Корни полинома определения местоположения ошибки могут быть найдены путем исчерпывающего поиска. Локаторы ошибок Иксk являются обратными этим корням. Порядок коэффициентов полинома определения ошибки может быть изменен на обратный, и в этом случае корни этого обратного полинома являются локаторами ошибок. (не их обратные ). Чиен поиск - эффективная реализация этого шага.

Рассчитайте значения ошибок
Как только локаторы ошибок Иксk известны, значения ошибок могут быть определены. Это можно сделать прямым решением для Yk в уравнения ошибок матрицу, приведенную выше, или используя Алгоритм Форни.
Рассчитайте места ошибок
Рассчитать яk взяв базу журнала из Иксk. Обычно это делается с помощью предварительно вычисленной таблицы поиска.
Исправьте ошибки
Наконец, e (x) генерируется из яk и еяk а затем вычитается из r (x), чтобы получить первоначально отправленное сообщение s (x) с исправленными ошибками.
пример
Рассмотрим код Рида – Соломона, определенный в GF(929) с участием α = 3 и т = 4 (это используется в PDF417 штрих-коды) для кода RS (7,3). Генераторный полином равен

Если полином сообщения п(Икс) = 3 Икс2 + 2 Икс + 1, то систематическое кодовое слово кодируется следующим образом.


Ошибки при передаче могут привести к получению этого сообщения.

Синдромы рассчитываются путем оценки р во власти α.



С помощью Гауссово исключение:

- Λ (х) = 329 х2 + 821 x + 001, с корнями x1 = 757 = 3−3 и х2 = 562 = 3−4
Коэффициенты можно поменять местами, чтобы получить корни с положительными показателями, но обычно это не используется:
- R (х) = 001 х2 + 821 x + 329, с корнями 27 = 33 и 81 = 34
с журналом корней, соответствующим местоположениям ошибок (справа налево, ячейка 0 - это последний член в кодовом слове).
Чтобы вычислить значения ошибок, примените Алгоритм Форни.
- Ω (x) = S (x) Λ (x) mod x4 = 546 х + 732
- Λ '(х) = 658 х + 821
- е1 = −Ω (x1) / Λ '(x1) = 074
- е2 = −Ω (x2) / Λ '(x2) = 122
Вычитание е1 Икс3 и е2 Икс4 от полученного многочлена р воспроизводит исходное кодовое слово s.
Декодер Берлекампа – Месси
В Алгоритм Берлекампа-Месси является альтернативной итерационной процедурой поиска полинома локатора ошибок.Во время каждой итерации он вычисляет несоответствие на основе текущего экземпляра Λ (x) с предполагаемым количеством ошибок. е:

а затем регулирует Λ (Икс) и е так что пересчитанное Δ будет равно нулю. Статья Алгоритм Берлекампа-Месси есть подробное описание процедуры. В следующем примере C(Икс) используется для представления Λ (Икс).
пример
Используя те же данные, что и в приведенном выше примере Peterson Gorenstein Zierler:
| п | Sп+1 | d | C | B | б | м |
|---|---|---|---|---|---|---|
| 0 | 732 | 732 | 197 Икс + 1 | 1 | 732 | 1 |
| 1 | 637 | 846 | 173 Икс + 1 | 1 | 732 | 2 |
| 2 | 762 | 412 | 634 Икс2 + 173 Икс + 1 | 173 Икс + 1 | 412 | 1 |
| 3 | 925 | 576 | 329 Икс2 + 821 Икс + 1 | 173 Икс + 1 | 412 | 2 |
Окончательное значение C - многочлен локатора ошибок, Λ (Икс).
Евклидов декодер
Другой итерационный метод вычисления как полинома локатора ошибок, так и полинома значения ошибки основан на адаптации Сугиямы расширенный алгоритм Евклида .
Определим S (x), Λ (x) и Ω (x) для т синдромы и е ошибки:



Ключевое уравнение:

Для т = 6 и е = 3:

Средние члены равны нулю из-за связи между Λ и синдромами.
Расширенный алгоритм Евклида может найти серию многочленов вида
- Ая(Икс) S(Икс) + Bя(Икс) Икст = ря(Икс)
где степень р уменьшается как я увеличивается. Однажды степень ря(Икс) < т/ 2, то
Ая(х) = Λ (х)
Bя(х) = −Q (х)
ря(х) = Ω (х).
B (x) и Q (x) не нужно сохранять, поэтому алгоритм становится:
- р−1 = хт
- р0 = S (х)
- А−1 = 0
- А0 = 1
- я = 0
- а степень Rя ≥ т / 2
- я = я + 1
- Q = Ri-2 / Ря-1
- ря = Ri-2 - Q Rя-1
- Ая = Аi-2 - Q Aя-1
чтобы установить младший член Λ (x) равным 1, разделите Λ (x) и Ω (x) на Aя(0):
- Λ (х) = Ая / Ая(0)
- Ω (x) = Rя / Ая(0)
Ая(0) - постоянный член (младшего порядка) Aя.
пример
Используя те же данные, что и в приведенном выше примере Петерсона – Горенштейна – Цирлера:
| я | ря | Ая |
|---|---|---|
| −1 | 001 х4 + 000 х3 + 000 х2 + 000 х + 000 | 000 |
| 0 | 925 х3 + 762 х2 + 637 х + 732 | 001 |
| 1 | 683 х2 + 676 х + 024 | 697 х + 396 |
| 2 | 673 х + 596 | 608 х2 + 704 х + 544 |
- Λ (х) = А2 / 544 = 329 х2 + 821 х + 001
- Ω (x) = R2 / 544 = 546 х + 732
Декодер с использованием дискретного преобразования Фурье
Для декодирования можно использовать дискретное преобразование Фурье.[15] Чтобы избежать конфликта с названиями синдромов, позвольте c(Икс) = s(Икс) закодированное кодовое слово. р(Икс) и е(Икс) такие же, как указано выше. Определить C(Икс), E(Икс), и р(Икс) как дискретные преобразования Фурье c(Икс), е(Икс), и р(Икс). поскольку р(Икс) = c(Икс) + е(Икс), и поскольку дискретное преобразование Фурье является линейным оператором, р(Икс) = C(Икс) + E(Икс).
Преобразовать р(Икс) к р(Икс) с помощью дискретного преобразования Фурье. Поскольку расчет для дискретного преобразования Фурье такой же, как расчет для синдромов, т коэффициенты р(Икс) и E(Икс) такие же, как синдромы:


Использовать через как синдромы (они такие же) и сгенерировать полином локатора ошибок, используя методы любого из вышеперечисленных декодеров.


Пусть v = количество ошибок. Сгенерируйте E (x), используя известные коэффициенты к , полином локатора ошибок, и эти формулы





Затем вычислите C(Икс) = р(Икс) − E(Икс) и обратное преобразование (полиномиальная интерполяция) C(Икс) производить c(Икс).
Декодирование за пределами исправления ошибок
В Граница синглтона заявляет, что минимальное расстояние d линейного блочного кода размером (п,k) ограничена сверху п − k + 1. Расстояние d обычно понималось, что возможность исправления ошибок ограничивается ⌊d/ 2⌋. Код Рида – Соломона достигает этой границы с равенством и, таким образом, может исправлять до (п − k + 1) / 2⌋ ошибок. Однако этот предел исправления ошибок не точен.
В 1999 году, Мадху Судан и Венкатесан Гурусвами в Массачусетском технологическом институте опубликовал «Улучшенное декодирование кодов Рида – Соломона и алгебраической геометрии», в котором представлен алгоритм, позволяющий исправлять ошибки, превышающие половину минимального расстояния кода.[16] Это относится к кодам Рида – Соломона и в более общем смысле к алгебро-геометрические коды. Этот алгоритм создает список кодовых слов (это список-декодирование алгоритм) и основан на интерполяции и факторизации многочленов по и его расширения.

Мягкое декодирование
Алгебраические методы декодирования, описанные выше, являются методами жесткого решения, что означает, что для каждого символа принимается жесткое решение о его значении. Например, декодер может связать с каждым символом дополнительное значение, соответствующее каналу. демодулятор уверенность в правильности обозначения. Появление LDPC и турбокоды, которые используют повторяющиеся мягкое решение методы декодирования распространения убеждений для достижения производительности исправления ошибок, близкой к теоретический предел, вызвало интерес к применению декодирования с мягким решением к обычным алгебраическим кодам. В 2003 году Ральф Кёттер и Александр Варди представил алгоритм полиномиального алгебраического декодирования списков с мягким решением для кодов Рида – Соломона, который был основан на работе Судана и Гурусвами.[17]В 2016 году Стивен Дж. Франке и Джозеф Х. Тейлор опубликовали новый декодер с мягким решением.[18]
Пример Matlab
Кодировщик
Здесь мы представляем простую реализацию Matlab для кодировщика.
функция[закодировано] =rsEncoder(msg, m, prim_poly, n, k)% RSENCODER Кодировать сообщение с помощью алгоритма Рида-Соломона % m - количество бит на символ % prim_poly: Примитивный многочлен p (x). Т.е. для DM - 301 % k - размер сообщения % n - общий размер (k + избыточный) % Пример: msg = uint8 ('Тест') % enc_msg = rsEncoder (сообщение, 8, 301, 12, число (сообщение)); % Получить альфа альфа = gf(2, м, prim_poly); % Получите порождающий многочлен Рида-Соломона g (x) g_x = генполия(k, п, альфа); % Умножьте информацию на X ^ (n-k) или просто добавьте нули в конце, чтобы % получить место для добавления избыточной информации msg_padded = gf([сообщение нули(1, п - k)], м, prim_poly); % Получить остаток от деления расширенного сообщения на % Порождающий многочлен Рида-Соломона g (x) [~, остаток] = деконв(msg_padded, g_x); % Теперь верните сообщение с избыточной информацией закодированный = msg_padded - остаток;конец% Найдите порождающий многочлен Рида-Соломона g (x), между прочим, это% то же, что и функция rsgenpoly в Matlabфункцияг =генполия(k, n, альфа)г = 1; % Умножение на поле Галуа - это просто свертка для k = mod (1: n - k, n) г = Конв(г, [1 альфа .^ (k)]); конецконецДекодер
Теперь расшифровка:
функция[декодировано, error_pos, error_mag, g, S] =rsDecoder(закодировано, m, prim_poly, n, k)% RSDECODER Расшифровать сообщение, закодированное Ридом-Соломоном % Пример: % [dec, ~, ~, ~, ~] = rsDecoder (enc_msg, 8, 301, 12, numel (сообщение)) max_errors = этаж((п - k) / 2); orig_val = закодированный.Икс; % Инициализировать вектор ошибки ошибки = нули(1, п); г = []; S = []; % Получить альфа альфа = gf(2, м, prim_poly); % Найдите синдромы (проверьте, не разбивает ли сообщение генератор % полином результат равен нулю) Synd = поливал(закодированный, альфа .^ (1:п - k)); Синдромы = отделка(Synd); % Если все синдромы нулевые (полностью делимые), ошибок нет если пусто (Syndromes.x) расшифрованный = orig_val(1:k); error_pos = []; error_mag = []; г = []; S = Synd; вернуть; конец% Подготовьтесь к эвклидовому алгоритму (используется для поиска ошибки % полиномов) r0 = [1, нули(1, 2 * max_errors)]; r0 = gf(r0, м, prim_poly); r0 = отделка(r0); size_r0 = длина(r0); r1 = Синдромы; f0 = gf([нули(1, size_r0 - 1) 1], м, prim_poly); f1 = gf(нули(1, size_r0), м, prim_poly); g0 = f1; g1 = f0; % Выполните алгоритм Евклида на многочленах r0 (x) и Syndromes (x) в %, чтобы найти многочлен обнаружения ошибки в то время как правда % Сделайте длинное деление [частное, остаток] = деконв(r0, r1); % Добавьте нули частное = подушечка(частное, длина(g1)); % Найти частное * g1 и дополнить c = Конв(частное, g1); c = отделка(c); c = подушечка(c, длина(g0)); % Обновить g как коэффициент g0 * g1 г = g0 - c; % Проверить, меньше ли степень остатка (x) max_errors если все (остаток (1: конец - max_errors) == 0) перерыв; конец% Обновить r0, r1, g0, g1 и удалить ведущие нули r0 = отделка(r1); r1 = отделка(остаток); g0 = g1; g1 = г; конец% Удалить ведущие нули г = отделка(г); % Найдите нули полинома ошибок на этом поле Галуа evalPoly = поливал(г, альфа .^ (п - 1 : - 1 : 0)); error_pos = gf(найти(evalPoly == 0), м); % Если ошибочной позиции не обнаружено, мы возвращаем полученную работу, потому что % по сути это ничего, что мы могли бы сделать и возвращаем полученное сообщение если isempty (error_pos) расшифрованный = orig_val(1:k); error_mag = []; вернуть; конец% Подготовьте линейную систему для решения полинома ошибок и нахождения ошибки % величины size_error = длина(error_pos); Синдром_Вальс = Синдромы.Икс; б(:, 1) = Синдром_Вальс(1:size_error); для idx = 1: size_error е = альфа .^ (idx * (п - error_pos.Икс)); ошибаться = е.Икс; э(idx, :) = ошибаться; конец% Решите линейную систему error_mag = (gf(э, м, prim_poly) \ gf(б, м, prim_poly))'; % Поместите величину ошибки в вектор ошибки ошибки(error_pos.Икс) = error_mag.Икс; % Принесите этот вектор в поле галуа errors_gf = gf(ошибки, м, prim_poly); % Теперь, чтобы исправить ошибки, просто добавьте закодированный код decoded_gf = закодированный(1:k) + errors_gf(1:k); расшифрованный = decoded_gf.Икс;конец% Удалить ведущие нули из массива Галуафункцияgt =отделка(г)gx = г.Икс; gt = gf(gx(найти(gx, 1) : конец), г.м, г.prim_poly);конец% Добавить ведущие нулифункцияxpad =подушечка(х, к)len = длина(Икс); если (len < k) xpad = [нули(1, k - len) Икс]; конецконецОригинальные декодеры вида Рида Соломона
Декодеры, описанные в этом разделе, используют исходное представление кодового слова Рида-Соломона как последовательность полиномиальных значений, где полином основан на кодируемом сообщении. Один и тот же набор фиксированных значений используется кодером и декодером, и декодер восстанавливает полином кодирования (и, возможно, полином обнаружения ошибки) из полученного сообщения.
Теоретический декодер
Рид и Соломон (1960) описал теоретический декодер, который исправляет ошибки, находя самый популярный полином сообщений. Декодер знает только набор значений к и какой метод кодирования использовался для генерации последовательности значений кодового слова. Исходное сообщение, многочлен и любые ошибки неизвестны. Процедура декодирования может использовать такой метод, как интерполяция Лагранжа на различных подмножествах из n значений кодового слова, взятых k за раз, для многократного создания потенциальных многочленов, пока не будет создано достаточное количество совпадающих многочленов, чтобы разумно устранить любые ошибки в полученном кодовом слове. После определения полинома любые ошибки в кодовом слове можно исправить путем повторного вычисления соответствующих значений кодового слова. К сожалению, во всех случаях, кроме самых простых, существует слишком много подмножеств, поэтому алгоритм непрактичен. Количество подмножеств - это биномиальный коэффициент, , а количество подмножеств невозможно даже для скромных кодов. Для код, который может исправить 3 ошибки, наивный теоретический декодер проверил бы 359 миллиардов подмножеств.




Декодер Berlekamp Welch
В 1986 году декодер, известный как Алгоритм Берлекампа – Велча был разработан как декодер, который может восстанавливать исходный полином сообщения, а также полином «локатора» ошибок, который производит нули для входных значений, соответствующих ошибкам, с временной сложностью O (n ^ 3), где n - число значений в сообщении. Восстановленный многочлен затем используется для восстановления (при необходимости пересчета) исходного сообщения.
пример
Используя RS (7,3), GF (929) и набор точек оценки ая = я − 1
- а = {0, 1, 2, 3, 4, 5, 6}
Если полином сообщения
- п(Икс) = 003 Икс2 + 002 Икс + 001
Кодовое слово
- c = {001, 006, 017, 034, 057, 086, 121}
Ошибки при передаче могут привести к получению этого сообщения.
- б = c + е = {001, 006, 123, 456, 057, 086, 121}
Ключевые уравнения:

Предположим максимальное количество ошибок: е = 2. Ключевые уравнения становятся:


С помощью Гауссово исключение:

- Q(Икс) = 003 Икс4 + 916 Икс3 + 009 Икс2 + 007 Икс + 006
- E(Икс) = 001 Икс2 + 924 Икс + 006
- Q(Икс) / E(Икс) = п(Икс) = 003 Икс2 + 002 Икс + 001
Пересчитать Р (х) где E (x) = 0: {2, 3} исправлять б в результате получено исправленное кодовое слово:
- c = {001, 006, 017, 034, 057, 086, 121}
Декодер гао
В 2002 году Шухонг Гао разработал улучшенный декодер на основе расширенного алгоритма Евклида. Gao_RS.pdf .
пример
Используя те же данные, что и в приведенном выше примере Берлекампа Велча:
- Интерполяция Лагранжа для я = От 1 до п





| я | ря | Ая |
|---|---|---|
| −1 | 001 х7 + 908 х6 + 175 х5 + 194 х4 + 695 х3 + 094 х2 + 720 х + 000 | 000 |
| 0 | 055 х6 + 440 х5 + 497 х4 + 904 х3 + 424 х2 + 472 х + 001 | 001 |
| 1 | 702 х5 + 845 х4 + 691 х3 + 461 х2 + 327 х + 237 | 152 х + 237 |
| 2 | 266 х4 + 086 х3 + 798 х2 + 311 х + 532 | 708 х2 + 176 х + 532 |
- Q(Икс) = р2 = 266 Икс4 + 086 Икс3 + 798 Икс2 + 311 Икс + 532
- E(Икс) = А2 = 708 Икс2 + 176 Икс + 532
делить Q(x) и E(x) по старшему коэффициенту при E(x) = 708. (Необязательно)
- Q(Икс) = 003 Икс4 + 916 Икс3 + 009 Икс2 + 007 Икс + 006
- E(Икс) = 001 Икс2 + 924 Икс + 006
- Q(Икс) / E(Икс) = п(Икс) = 003 Икс2 + 002 Икс + 001
Пересчитать п(Икс) где E(Икс) = 0 : {2, 3} исправлять б в результате получено исправленное кодовое слово:
- c = {001, 006, 017, 034, 057, 086, 121}
Смотрите также
- Код BCH
- Циклический код
- Чиен поиск
- Алгоритм Берлекампа-Месси
- Прямое исправление ошибок
- Алгоритм Берлекампа – Велча
- Сложенный код Рида – Соломона
Заметки
- ^ Авторы в[8] предоставить результаты моделирования, которые показывают, что для той же кодовой скорости (1/6) турбокоды превосходят сцепленные коды Рида-Соломона до 2 дБ (частота ошибок по битам ).
использованная литература
- Джилл, Джон (нет данных), EE387 Заметки № 7, Раздаточный материал № 28 (PDF), Стэнфордский университет, архив из оригинал (PDF) 30 июня 2014 г., получено 21 апреля, 2010
- Хонг, Джонатан; Веттерли, Мартин (август 1995), «Простые алгоритмы декодирования BCH» (PDF), Транзакции IEEE по коммуникациям, 43 (8): 2324–2333, Дои:10.1109/26.403765
- Линь, Шу; Костелло-младший, Дэниел Дж. (1983), Кодирование с контролем ошибок: основы и приложения, Нью-Джерси, Нью-Джерси: Прентис-Холл, ISBN 978-0-13-283796-5
- Мэсси, Дж. Л. (1969), «Синтез регистров сдвига и декодирование BCH» (PDF), IEEE Transactions по теории информации, ИТ-15 (1): 122–127, Дои:10.1109 / tit.1969.1054260
- Петерсон, Уэсли В. (1960), "Процедуры кодирования и исправления ошибок для кодов Бозе-Чаудхури", Сделки IRE по теории информации, IT-6 (4): 459–470, Дои:10.1109 / TIT.1960.1057586
- Рид, Ирвинг С.; Соломон, Гюстав (1960), "Полиномиальные коды над некоторыми конечными полями", Журнал Общества промышленной и прикладной математики, 8 (2): 300–304, Дои:10.1137/0108018
- Уэлч, Л. Р. (1997), Первоначальный взгляд на коды Рида – Соломона (PDF), Конспект лекций
дальнейшее чтение
- Берлекамп, Элвин Р. (1967), Недвоичное декодирование BCH, Международный симпозиум по теории информации, Сан-Ремо, Италия
- Берлекамп, Элвин Р. (1984) [1968], Алгебраическая теория кодирования (Пересмотренное издание), Laguna Hills, CA: Aegean Park Press, ISBN 978-0-89412-063-3
- Сипра, Барри Артур (1993), "Вездесущие коды Рида – Соломона", Новости SIAM, 26 (1)
- Форни младший, Г. (Октябрь 1965 г.), «О декодировании кодов BCH», IEEE Transactions по теории информации, 11 (4): 549–557, Дои:10.1109 / TIT.1965.1053825
- Кёттер, Ральф (2005), Коды Рида – Соломона, MIT Lecture Notes 6.451 (видео), архивировано с оригинал на 2013-03-13
- MacWilliams, F.J .; Слоан, Н. Дж. А. (1977), Теория кодов, исправляющих ошибки, Нью-Йорк, Нью-Йорк: Издательская компания Северной Голландии.
- Рид, Ирвинг С.; Чен, Сюэминь (1999), Кодирование с контролем ошибок для сетей передачи данных, Бостон, Массачусетс: Kluwer Academic Publishers
внешние ссылки
Информация и учебные пособия
- Введение в коды Рида – Соломона: принципы, архитектура и реализация (CMU)
- Учебное пособие по кодированию Рида – Соломона для обеспечения отказоустойчивости в RAID-подобных системах
- Алгебраическое мягкое декодирование кодов Рида – Соломона
- Викиверситет: коды Рида – Соломона для программистов
- Белая книга BBC R&D WHP031
- Гейзель, Уильям А. (август 1990 г.), Учебное пособие по кодированию с исправлением ошибок Рида – Соломона (PDF), Технический меморандум, НАСА, TM-102162
- Гао, Шухун (январь 2002 г.), Новый алгоритм декодирования кодов Рида-Соломона (PDF), Клемсон
- Составные коды автор Dr. Дэйв Форни (scholarpedia.org).
Реализации
- Кодек Рида – Соломона Schifra с открытым исходным кодом C ++
- Библиотека RSCode Генри Мински, кодировщик / декодер Рида – Соломона
- Библиотека программного декодирования Рида – Соломона с открытым исходным кодом C ++
- Реализация в Matlab ошибок и стираний декодирования Рида – Соломона
- Реализация Octave в коммуникационном пакете
- Реализация кодека Рида – Соломона на чистом Python
- ^ Рид и Соломон (1960)
- ^ Д. Горенштейн и Н. Цирлер, "Класс циклических линейных кодов с исправлением ошибок в символах p ^ m", J. SIAM, vol. 9, стр. 207-214, июнь 1961 г.
- ^ Коды исправления ошибок, автор W_Wesley_Peterson, 1961 г.
- ^ Коды исправления ошибок, автор W_Wesley_Peterson, второе издание, 1972 г.
- ^ Ясуо Сугияма, Масао Касахара, Сигейчи Хирасава и Тошихико Намекава. Метод решения ключевого уравнения для декодирования кодов Гоппа. Информация и контроль, 27: 87–99, 1975.
- ^ Имминк, К.А.С. (1994), «Коды Рида – Соломона и компакт-диск», в Wicker, Stephen B .; Бхаргава, Виджай К. (ред.), Коды Рида – Соломона и их приложения, IEEE Press, ISBN 978-0-7803-1025-4
- ^ Дж. Хагенауэр, Э. Оффер и Л. Папке, Коды Рида-Соломона и их приложения. Нью-Йорк IEEE Press, 1994 - стр. 433
- ^ а б Эндрюс, Кеннет С. и др. «Разработка кодов турбо и LDPC для приложений дальнего космоса». Протоколы IEEE 95.11 (2007): 2142-2156.
- ^ Лидл, Рудольф; Пильц, Гюнтер (1999). Прикладная абстрактная алгебра (2-е изд.). Вайли. п. 226.
- ^ Увидеть Лин и Костелло (1983), п. 171), например.
- ^ «Аналитические выражения, используемые в кодировании и BERTool». В архиве с оригинала на 2019-02-01. Получено 2019-02-01.
- ^ Пфендер, Флориан; Циглер, Гюнтер М. (сентябрь 2004 г.), «Целующиеся числа, упаковки сфер и некоторые неожиданные доказательства» (PDF), Уведомления Американского математического общества, 51 (8): 873–883, в архиве (PDF) из оригинала 2008-05-09, получено 2009-09-28. Объясняет теорему Дельсарта-Гётальса-Зейделя в контексте кода исправления ошибок для компакт-диск.
- ^ Д. Горенштейн и Н. Цирлер, "Класс циклических линейных кодов с исправлением ошибок в символах p ^ m", J. SIAM, vol. 9. С. 207–214, июнь 1961 г.
- ^ Коды исправления ошибок Уэсли Петерсон, 1961 г.
- ^ Шу Линь и Дэниел Дж. Костелло-младший, "Кодирование с контролем ошибок", второе издание, стр. 255–262, 1982, 2004
- ^ Гурусвами, V .; Судан, М. (сентябрь 1999 г.), «Улучшенное декодирование кодов Рида – Соломона и кодов алгебраической геометрии», IEEE Transactions по теории информации, 45 (6): 1757–1767, CiteSeerX 10.1.1.115.292, Дои:10.1109/18.782097
- ^ Кёттер, Ральф; Варди, Александр (2003). «Алгебраическое декодирование с мягким решением кодов Рида – Соломона». IEEE Transactions по теории информации. 49 (11): 2809–2825. CiteSeerX 10.1.1.13.2021. Дои:10.1109 / TIT.2003.819332.
- ^ Franke, Стивен Дж .; Тейлор, Джозеф Х. (2016). "Декодер Soft-Decision с открытым исходным кодом для кода Рида-Соломона JT65 (63,12)" (PDF). QEX (Май / июнь): 8–17. В архиве (PDF) из оригинала на 2017-03-09. Получено 2017-06-07.